Using Datastream to Replicate PostgreSQL Tables to BigQuery

Datastream is a serverless, user-friendly Google Managed Service in the Google Cloud Platform (GCP) for Change Data Capture (CDC). It is designed to enable reliable data replication with minimal latency.
Prerequisites
- PostgreSQL source database (version 9.6 or higher)
- Google Cloud account
- REPLICA IDENTITY FULL setting in PostgreSQL
- Required IAM permissions:Datastream AdminBigQuery Data EditorService Account User
Step 1: Setting Up PostgreSQL Environment
For testing purposes, you'll need a PostgreSQL environment. You can run PostgreSQL either on a VPS, local machine, or Google Cloud VM using the following docker-compose.yml file. Simply run docker compose up -d to start:
version: '3.8'
services:
postgres:
image: postgres:13
container_name: postgres
command: ["postgres", "-c", "wal_level=logical"]
ports:
- 5432:5432
volumes:
- pgvolume:/var/lib/postgresql/data
environment:
- POSTGRES_USER=admin
- POSTGRES_PASSWORD=admin
- POSTGRES_DB=postgres
restart: always
volumes:
pgvolume:This setup:
- Uses PostgreSQL 13
- Enables logical replication (
wal_level=logical) - Exposes port 5432
- Creates a persistent volume for data storage
- Default credentials (admin/admin)
Step 2: Setting Up PostgreSQL Test Tables and Replication
You can connect to your PostgreSQL database using a graphical tool like DBeaver, or alternatively via CLI:
docker exec -it postgres psql -U admin -d postgres-- Create test table
CREATE TABLE cdc_testing (
id INTEGER,
name text,
process_date DATE,
PRIMARY KEY (id)
);
-- Create logical replication slot
SELECT pg_create_logical_replication_slot('datastream_slot_cdc', 'pgoutput');
-- Create publication
CREATE PUBLICATION datastream_pub FOR TABLE cdc_testing;Important configuration names to note:
- Replication slot name:
datastream_slot_cdc - Publication name:
datastream_pub

Step 3: Creating Datastream Stream
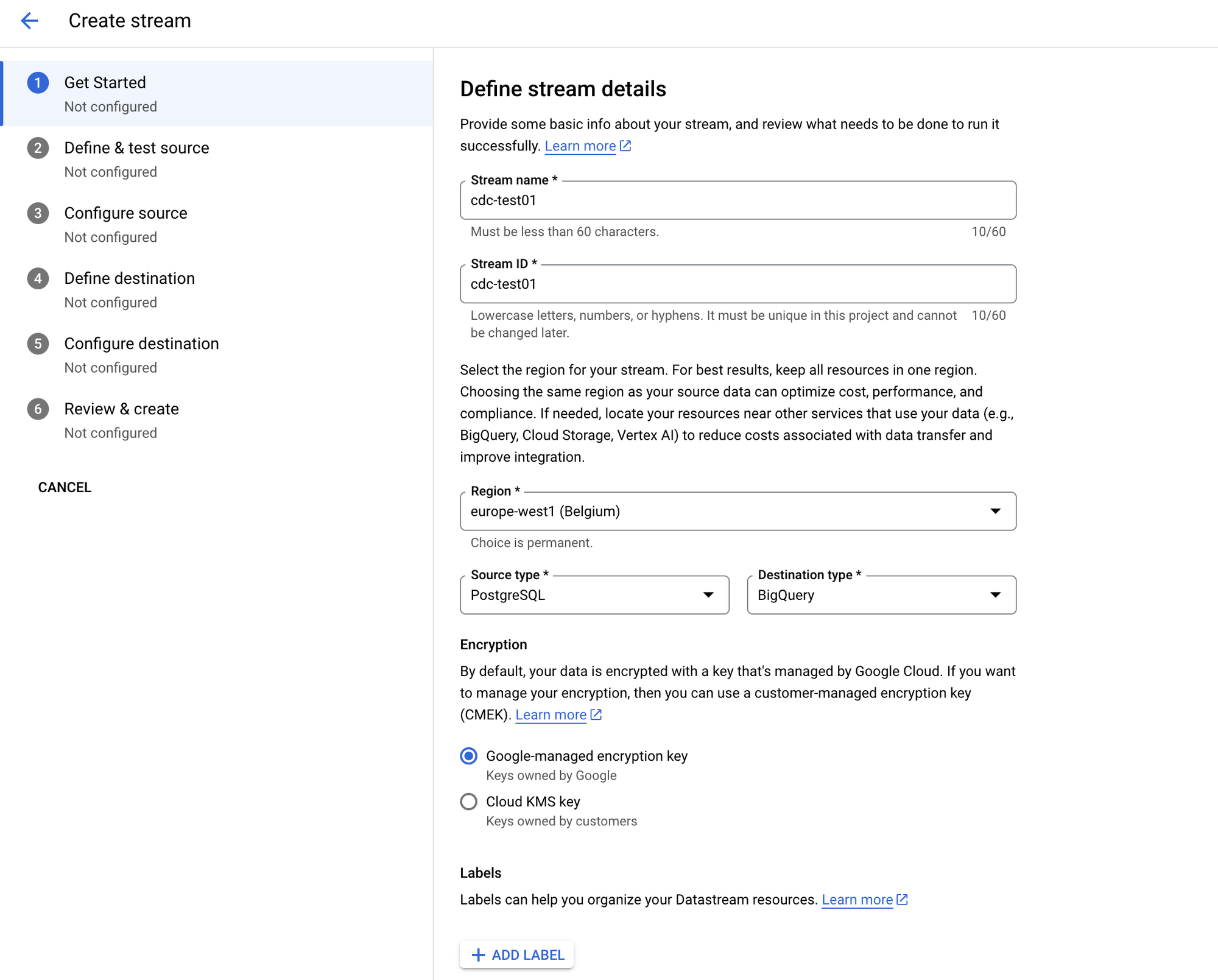
- Navigate to Google Cloud Console and search for "Datastream" in the search bar
- Click on the Create Stream button
- Configure your stream:
- Give your stream a meaningful name
- Select the closest region to your source database
- Choose PostgreSQL as the Source type
- Select BigQuery as the Destination type
- Click Next
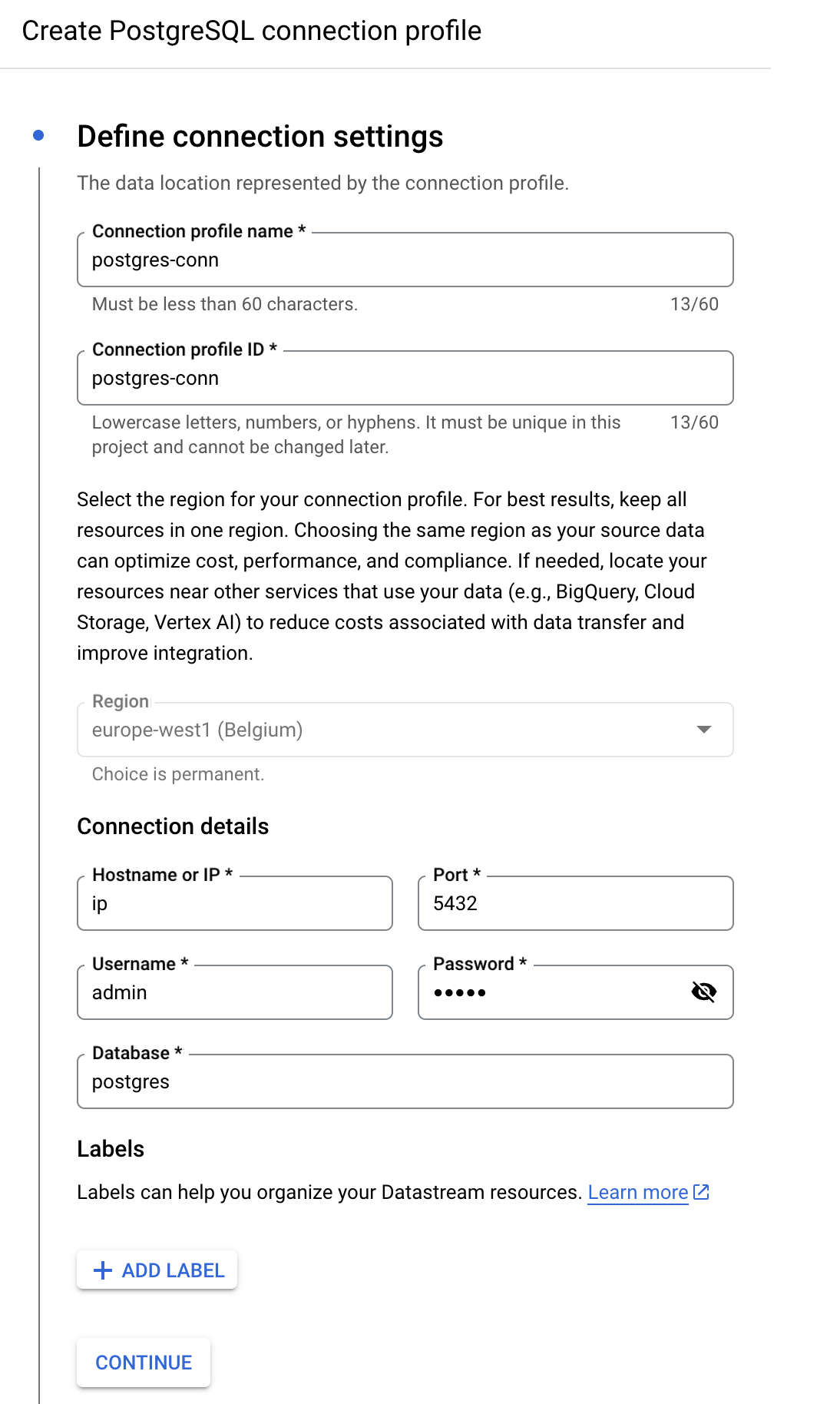
- Configure PostgreSQL Connection
- Enter the PostgreSQL connection details:
- Hostname/IP
- Port: 5432
- Username: admin
- Password: admin
- Database: postgres
- Select IP Allowlisting as the connectivity method
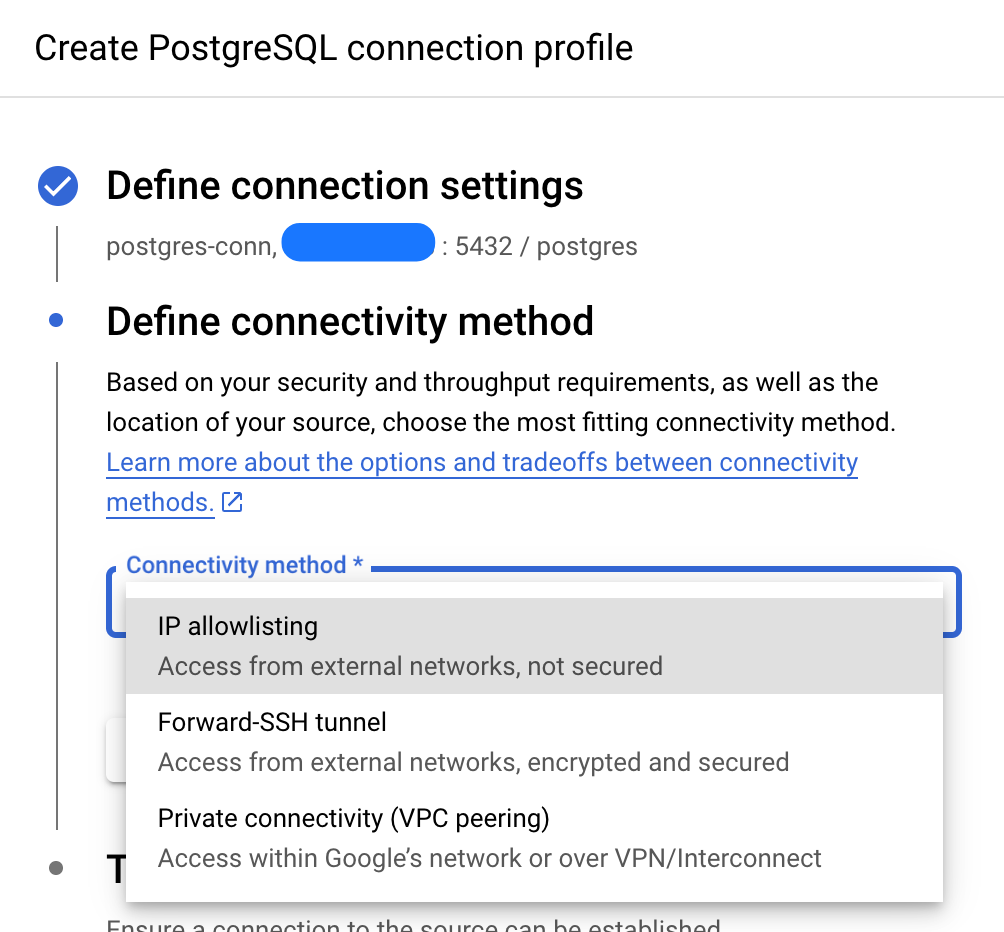
- Add the provided IP addresses to your allowlist to grant Datastream access to your PostgreSQL database (if necessary, but it is not necessary for test purposes)
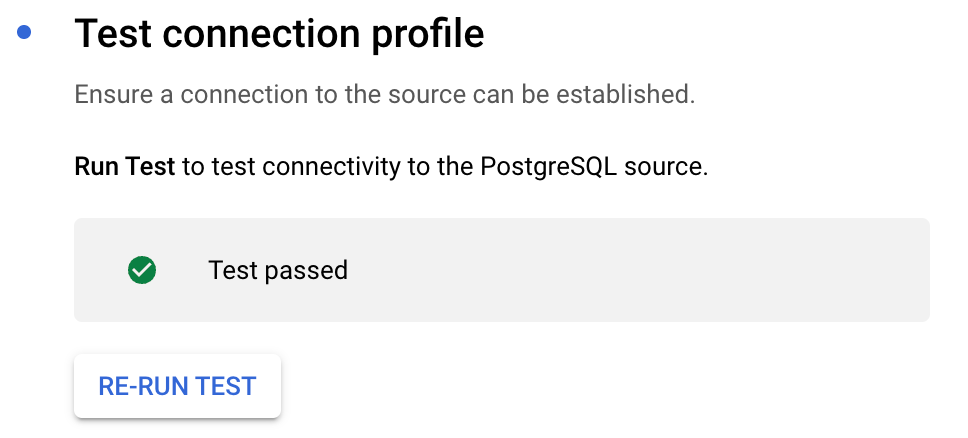
- Configure Source configuration:
- Enter the replication slot name:
datastream_slot_cdc - Enter the publication name:
datastream_pub - Select tables to replicate (in our case,
cdc_testingtable) - Click Continue
- Enter the replication slot name:
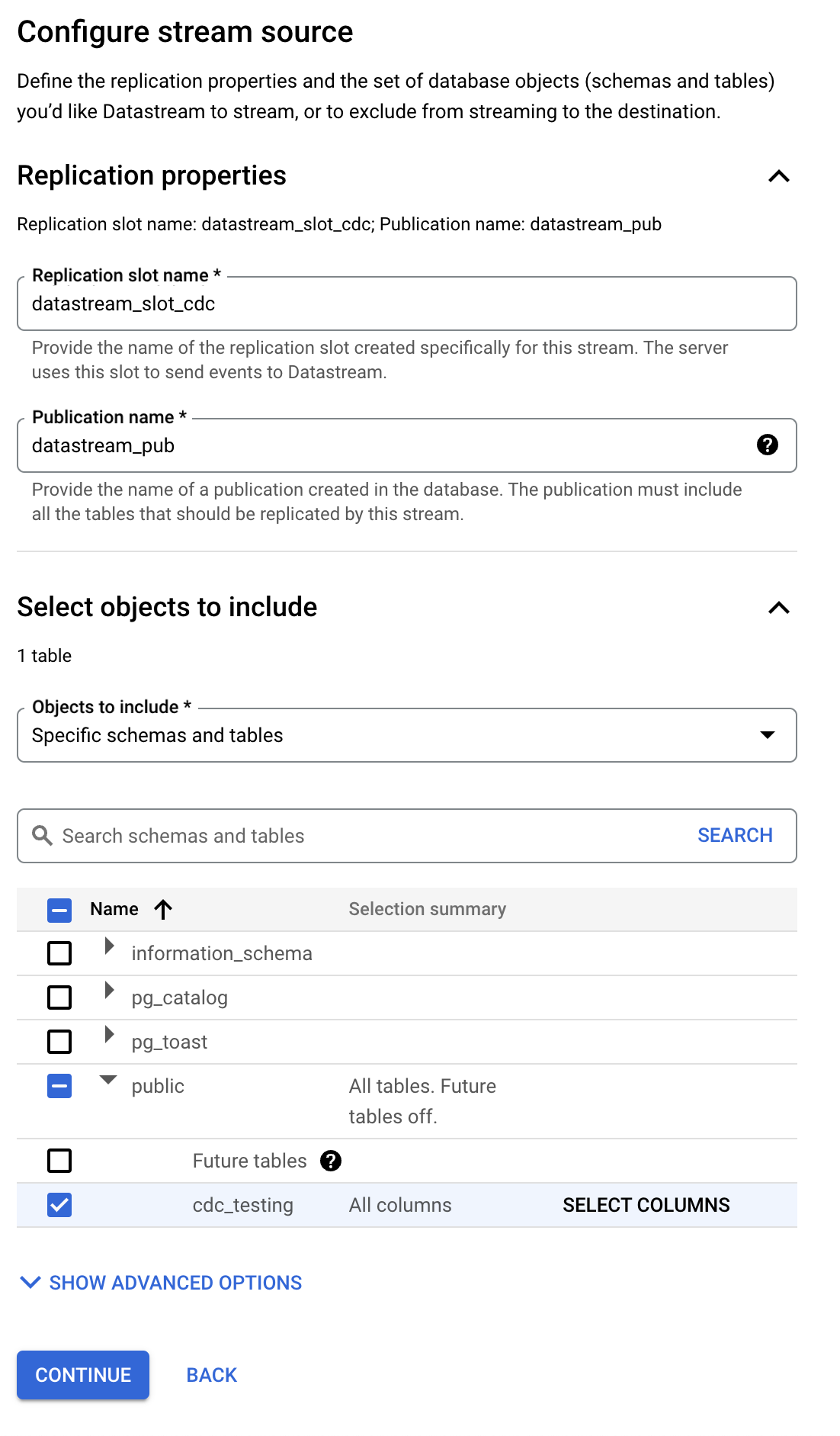
- Configure BigQuery Destination:
- Schema Grouping: Select "Single dataset for all schemas" (tables will be named like
public_cdc_testing) - Dataset: Choose an existing dataset or create a new one
- Write Mode:
- Merge: Updates data in BigQuery as changes occur in the source
- Append-only: Maintains a history of all changes
- Staleness Limit: Set to "0 seconds" for testing purposes
- Click Create & Start to initialize the stream
- Schema Grouping: Select "Single dataset for all schemas" (tables will be named like
Note: The stream initialization process may take approximately 5 minutes. Once it's ready, we can proceed with inserting test data into PostgreSQL
Step 4: Testing the Data Flow
Once the stream is started, you can test the replication by inserting some test data into PostgreSQL:
-- Insert test data into PostgreSQL
INSERT INTO public.cdc_testing (id, name, process_date)
VALUES
(1,'ahmet',current_date);
-- Update the record
UPDATE public.cdc_testing
SET name = 'updated_name'
WHERE id = 1;
-- Delete the record
DELETE FROM public.cdc_testing
WHERE id = 1;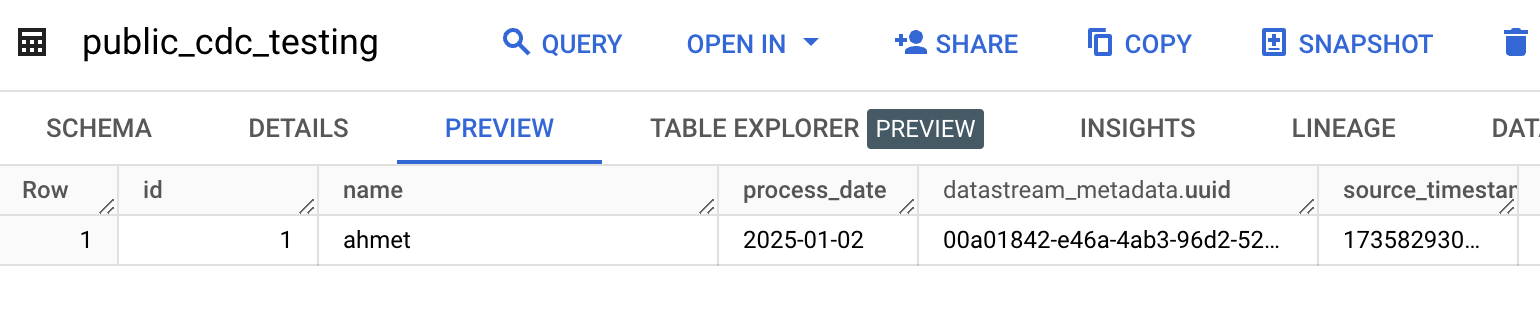
Advantages
- Zero-Code Data Migration: Ideal for transferring data to Google ecosystem without writing any code
- Source Synchronization: As long as there are no issues with the source (e.g., binary log corruption), data flow will continue smoothly
- Easy Recovery: If issues occur, you can drop the BigQuery table and restart the datastream to get a clean, up-to-date copy
- Simple Backfill: If you accidentally drop a table, you can easily recreate it using the INITIATE BACKFILL button
- Schema Evolution: New columns added to the source table are automatically added to BigQuery
- Change Tracking:
datastream_metadatacolumns help track what data has changed
Disadvantages
- Lack of Partitioning: Tables are not partitioned by default
- Manual Work Required: You need to either manually configure partitioning or create a new table after stopping the stream for partition setup
Step 5: Partitioning in BigQuery
Creating a Partitioned Table Before Starting the Stream
If you want to create a partitioned table before starting the stream:
CREATE TABLE `project-id.datastream.public_cdc_testing` (
id INT64 PRIMARY KEY NOT ENFORCED,
name STRING,
process_date DATE,
datastream_metadata ARRAY<STRUCT<uuid STRING, source_timestamp INT64>>
)
PARTITION BY process_date -- PARTITION BY _PARTITIONDATE
CLUSTER BY id,nameAdding Partitioning to an Existing Table
To add partitioning to an existing table:
- First, pause the datastream
- Create a new partitioned table:
CREATE TABLE `project-id.datastream.public_cdc_testing_new` (
id INT64,
name STRING,
process_date DATE,
datastream_metadata ARRAY<STRUCT<uuid STRING, source_timestamp INT64>>
)
PARTITION BY process_date
CLUSTER BY id,name- Copy the data:
INSERT INTO `project-id.dataset.public_cdc_testing_new`
SELECT id, name, process_date, [datastream_metadata]
FROM `project-id.dataset.public_cdc_testing`;- Drop the old table and rename the new one:
DROP TABLE `project-id.dataset.public_cdc_testing`;
ALTER TABLE `project-id.dataset.public_cdc_testing_new`
RENAME TO `public_cdc_testing`;- Add primary key:
ALTER TABLE `project-id.dataset.public_cdc_testing`
ADD PRIMARY KEY(id) NOT ENFORCED;Note: If there are primary key issues between PostgreSQL and BigQuery tables, you might need to remove the primary key from both tables. The primary key in BigQuery can be added after the stream works correctly.
Conclusion
In this guide, we explored how to replicate data from PostgreSQL to BigQuery using Datastream, how to optimize the system, and how to set up partitioning. Thanks to the features provided by Datastream, you can create a reliable data flow without writing code and customize it according to your needs.
Thanks for reading.
